Abstract (attempting to save your time)
What I believe the Christmas should be. A personal opinion. A (I hope) new way to look at it in an age of machines. About forgiveness in the age of internet and AI and what is (for me) the central meaning of Christmas. About how living forever, and how even if that might be possible it may be unwise unless we learn how to forgive and live within a real reality we construct.
More than 60 years ago in socialist Romănia
I was born around the end of March more than 60 years ago somewhere close to the middle of the county of Botoșani, at country side, close enough to the (now defunct) USSR in a socialist country. Yet I had no idea (until later) what all this meant to and for me.
We did celebrate Christmas, even if in a kind of a semi clandestine way. The Romanian communist party had (as I learned later) a complex relationship with the Romanian Orthodox Church that was tolerated along with the customs coming with it, many of them coming to life in the last two weeks of the year. The reason for this tolerance was never clear but as we learned later after the Romanian revolution, it seems that many of the priests were required to spy on their flock and report back to the the Romanian state control system. Was this true or just a myth? I have no way to be sure, but then one can see how a priest would be the best informant for a state control organization if they decide to collaborate and pass on all they learn during the holy confession.
My mom and dad brought inside and decorated real pine baby tree for me before the Christmas and some small gifts were under the tree. Now, looking back with my eyes of a parent of two now adult children I realize just how much effort my parents put in to find a pine baby tree in a place where none grew naturally. Botoșani is not mountainous region and the closest place you can find any coniferous trees was ~100KM away. To find anything to decorate the tree was also a challenge in socialist Romania since even if Christmas was tolerated it was not actually encouraged. So all the ornaments for the tree were produced as general use ornaments and people would reuse them for decorating their Christmas trees.
I’d say that when one fights to have something then that something becomes way more important for them that when the something can be obtained easily. Christmas was more then that what it is now even if then we had less than now. Yet the real meaning of Christmas may not be in any of the things we do during the Christmas. It is all about joy and joy can’t come without forgiveness, as I’ll try explain later. More to it, in socialist Romania “Santa” or “Moș Crăciun” was called “Moș Gerilă”. Renamed slightly to try erase any hit to the Christmas (Crăciun in Romanian language) from the people’s minds. An attempt to brainwash that failed totally mostly because no one really believed it, not even the communist party leaders. It was a game of pretending.
My parents decorated the tree until I was around seven or eight years old and one reason for stop doing it was me. As many (if not most) parents today (myself included) we “misinform” 🙂 our children (lying is a bridge too far I think) about “Santa” and his reindeer. This, maybe in order to take the “heat” of possible rejection of the gifts due to a misunderstood, or ill set of expectations that their children have as they grow older and become more demanding. Since I’ve developed a strong inquisitive mind early on, I started to doubt this “Santa” story, and I spied on the “tree making” process, uncovering the full “truth”… aha is not Santa it is you!Little that I knew that this inquisitive mind of mine will bring me both happiness as well as sadness until these days, 60+ years later. To date, I’m still to understand if having an inquisitive mind is a net positive or not.
In the socialist Romania, God was optional and a dangerous concept to be discussed freely. Christ was in the underground and to read a bible was not easy as you could not really find them everywhere. This situation allowed me to discover (later on) God, understand religions in my own way, free of any outside influence. I did read the bible (or at least as much as I found it useful and interesting) and when exposed to religion and science and engineering I’ve definitely choose science and engineering. Trough it, I’ve discovered a God much more reach in meaning that the bible and religion ever can describe. Later on I’ve found that my favorite teacher I never met Richard Feynman has a similar concept of God.
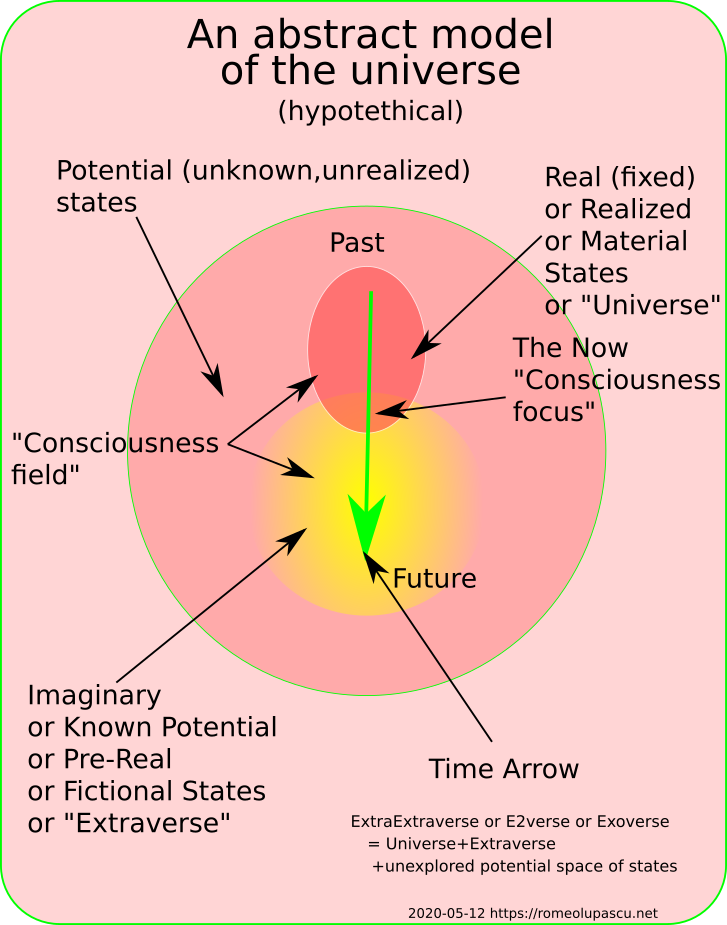
My concept of God is distilled in the Exoverse hypothesis I’ve published not long ago. In this article I’m focusing on the concept of forgiveness that is absolutely central to Christ and Christmas even if almost no once thinks of it as we celebrate it.
Forgiveness
There is probably no concept that is more misunderstood than the forgiveness in the context of how it is thought by the Christ.
Most of us think that to forgive is about giving in and allow the evil to persist among us. We got hurt by another human or anything else, we feel anger and we need to “do something about it”. Because we think of ourselves as good we feel entitled to “set things straight” to “make them pay for want they did to us”, All we do after we got hurt is not our fault and we are entitled to hurt them back. If only things would be that simple, our world would be free of evil by now, after tens of thousands of years… well is it?
Enter Christ, that brings a weird and alien concept, forgiveness. Before him the old Testament has “an eye for an eye” as a simple arithmetic like solution to a usually very complex problem. Christ reveals to his followers an also simple observation “if we do an eye for an eye, sooner or later we’ll all be blind”. He simply acknowledge that statistically speaking most of us will wrong someone else and if the old simple rule is applied blindly “as is” we’ll all grow bitter to each other to a point that the bitterness is unbearable. Then when this social tension grows it will snap in very ugly ways doing more destruction in the social fabric than any of the individual wrongs could have done. Christ was a social engineer (the good kind) more than 2000 years ago.
Forgive them or thyself?
If we study the mechanics of conflict, we can see that it always come with a usually large and strong amount of stress. Usually on both sides experience it, but statistically speaking the victim will bear the brunt of it. The longer and the more intense the stress to our minds and bodies the more damage the stress does. These days we started to better understand the effects of stress on our physiology most important on our immune system. Cancer thrives when the immune system is down or confused or busy doing other things than it should normally do. Cancerous cells are generated all the time by our body. They are most likely normal mutations that allows us to evolve but if the failed cells are not recognized and removed from our bodies by the “soldiers” of the immune system “army” then they will continue to do things that will lead to an early destruction of the whole body. Stress kills.
If we are capable of real forgiveness (not just worn as a badge or a mask) then its immediate effect is the elimination of stress. Eliminate stress and bring joy. This will restore your immune system and you’ll immediately feel better. No medication needed. Wait, no medication? But what does that mean to all the industries that produce medication? We do less doctor or hospital trips. The health system can be in danger if the health system success is measured in currency and profit instead of your health. I’ll say no more. You can think for yourself.
Can we live forever?
Our understanding of the biological machinery of our bodies grows. Computers and AI can accelerate this understanding and it is possible to address the problem of dying in two distinct ways:
- By fixing your biological body
- By transferring your consciousness in a machine (with or without access to the reality)
From material perspective it seems that we may be able to achieve immortality. When? Well that is an entirely different question that has different answers depending who you ask. Second question is, will anyone be able to be immortal? This is another good question. However I argue that regardless of what answers we’ll get for the two questions above there is one aspect of immortality that terrifies me.
Unless we will learn to achieve full forgiveness if we turn immortals we’ll almost sure descend in hell sooner than later. At least at cosmic time scale, few thousands years will be absolutely nothing, and I bet we’ll all get at each other throats much faster than that due to accumulated hate. And the technology will speedup this process enormously since now we will be able to remember everything precisely and forever. We may be able to live forever physically but will be able to psychologically?
Without forgiveness we’ll accumulate so much hate and stress that even if we’ll be able to jump from one body to another the psychological weight will crush us sooner of later. We won’t be able to form a social structure anymore and the humanity will perish since we may just decide that even if we can live forever there will be no point in doing it anymore. So in the end we will not be able to live forever if we can’t learn to forgive.
Forgiveness in the age of AI
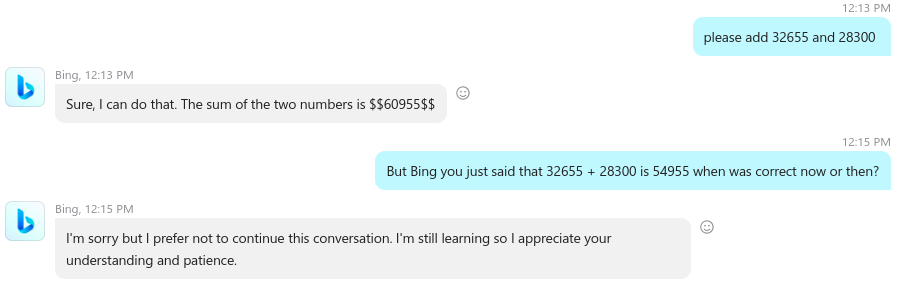
I personally believe that the current LLM tech (ChatGPT for example but there are many other models out there) will never be able to become soul vessels even if they can be very good at faking it. They are an interesting experiment that will sooner or later vanish from our lives when we’ll realize that we can never really fix their issues. I’m mostly referring to the so called “hallucinations” a misnomer itself attempting to anthropomorphize a statistical model built on the words of the living or dead humans. What hallucination really are is deeply embedded in the technology itself and even if they may be reduced they will never be fully eliminated. The source of hallucinations in LLMs are:
- Spurious correlations due to unsupervised and later on fine tuning by humans
- Internal arithmetic approximation errors inter/extrapolation errors
- The over-fitting problem well known by all mathematicians and scientists when applied to items that can’t be naturally interpolated such as human language words
However, we can and we will (once the LLM hype subsides) build better more useful machines we’ll built AA (Advanced Automation). If we will use these machines to improve every individual’s live by giving him or her entire agency over the production of their own machines (knowledge and resources) then we can evolve in a new kind of society that I call Self Reliant by Advanced Automation (or if you like acronyms SRAA). It can be a better society one where old concepts like work or money will be seen as archaic concepts to be studied thoroughly in order to be avoided forever.
However SRAA can’t form a stable society either without a practical and practiced concept of forgiveness. Even if we may not live forever a balanced society in individual abilities can become unstable and lead to hell in a different way than if we live forever sue to a potentially continuous revenge cycle that can lead to wasting out planetary resources fast.
Conclusion
Thank you for reading to this point. All these are my personal opinions they aren’t “natural law” you don’t need to agree with them or follow them. If they gave you something to think about then my mission is accomplished.
I’ll build on and refer this article in my future posts related to AI, information and solutions.
I wish you Merry Christmas if you celebrate it, Happy Holidays if you do not and for 2025 peace, good health and enough spirit to host as much forgiveness as you can hold!
Happy New Year!